On the Importance of Hyperparameter Optimization for Model-based Reinforcement Learning
Abstract
Model-based Reinforcement Learning (MBRL) is a promising framework for learning control in a data-efficient manner. MBRL algorithms can be fairly complex due to the separate dynamics modeling and the subsequent planning algorithm, and as a result, they often possess tens of hyperparameters and architectural choices. For this reason, MBRL typically requires significant human expertise before it can be applied to new problems and domains. To alleviate this problem, we propose to use automatic hyperparameter optimization (HPO). We demonstrate that this problem can be tackled effectively with automated HPO, which we demonstrate to yield significantly improved performance compared to human experts. In addition, we show that tuning of several MBRL hyperparameters dynamically, i.e. during the training itself, further improves the performance compared to using static hyperparameters which are kept fixed for the whole training. Finally, our experiments provide valuable insights into the effects of several hyperparameters, such as plan horizon or learning rate and their influence on the stability of training and resulting rewards.
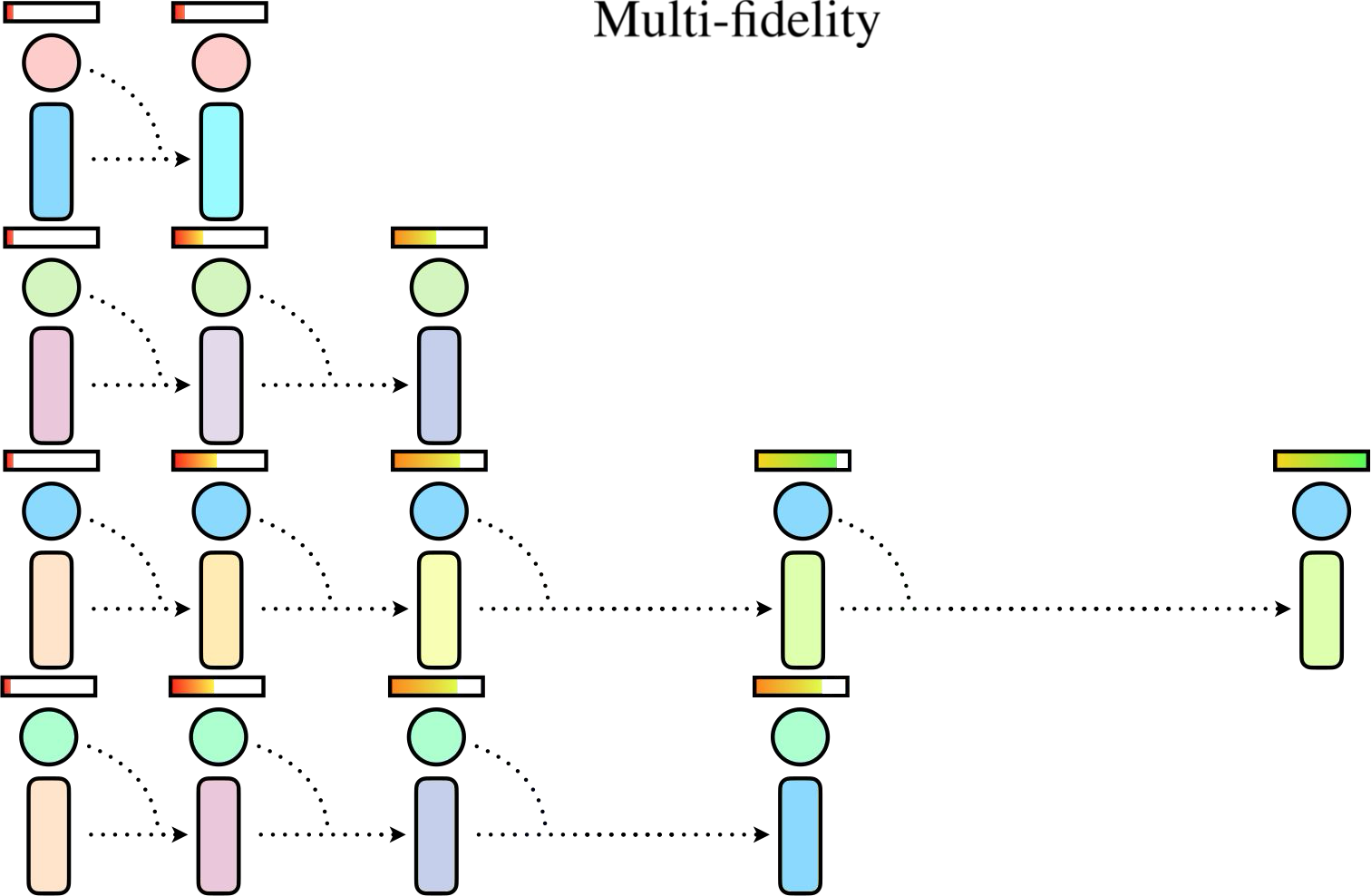
Highlights
- Why HPO for MBRL? Model-based RL pipelines stack dynamics learning and planning, exposing tens of interacting hyperparameters that are usually hand-tuned by experts.
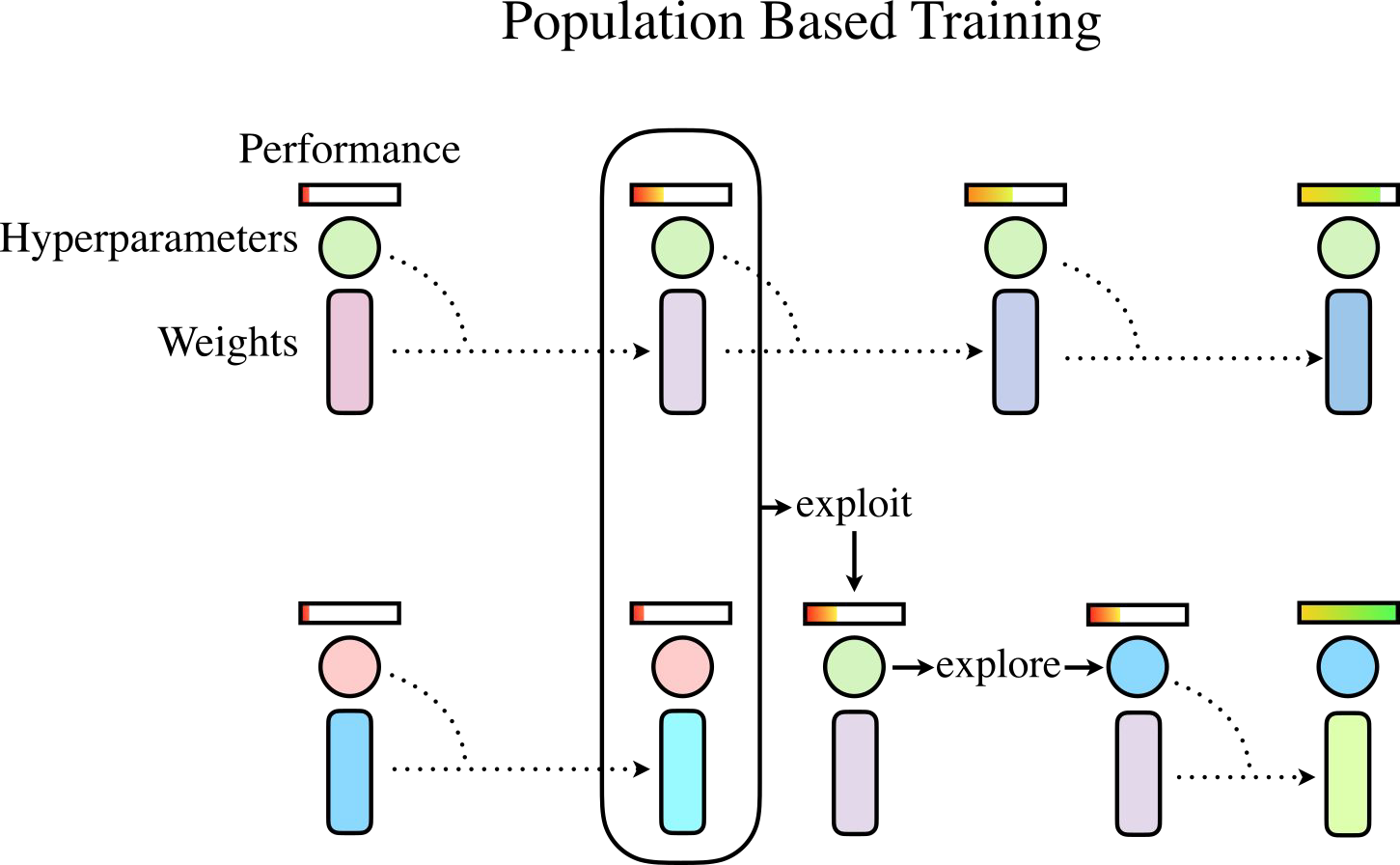
- Approach. We apply automated HPO — including multi-fidelity search (top-right) and Population-Based Training (top-left) — to MBRL, and additionally allow hyperparameters to be tuned dynamically during training. Figures are made by André Biedenkapp.
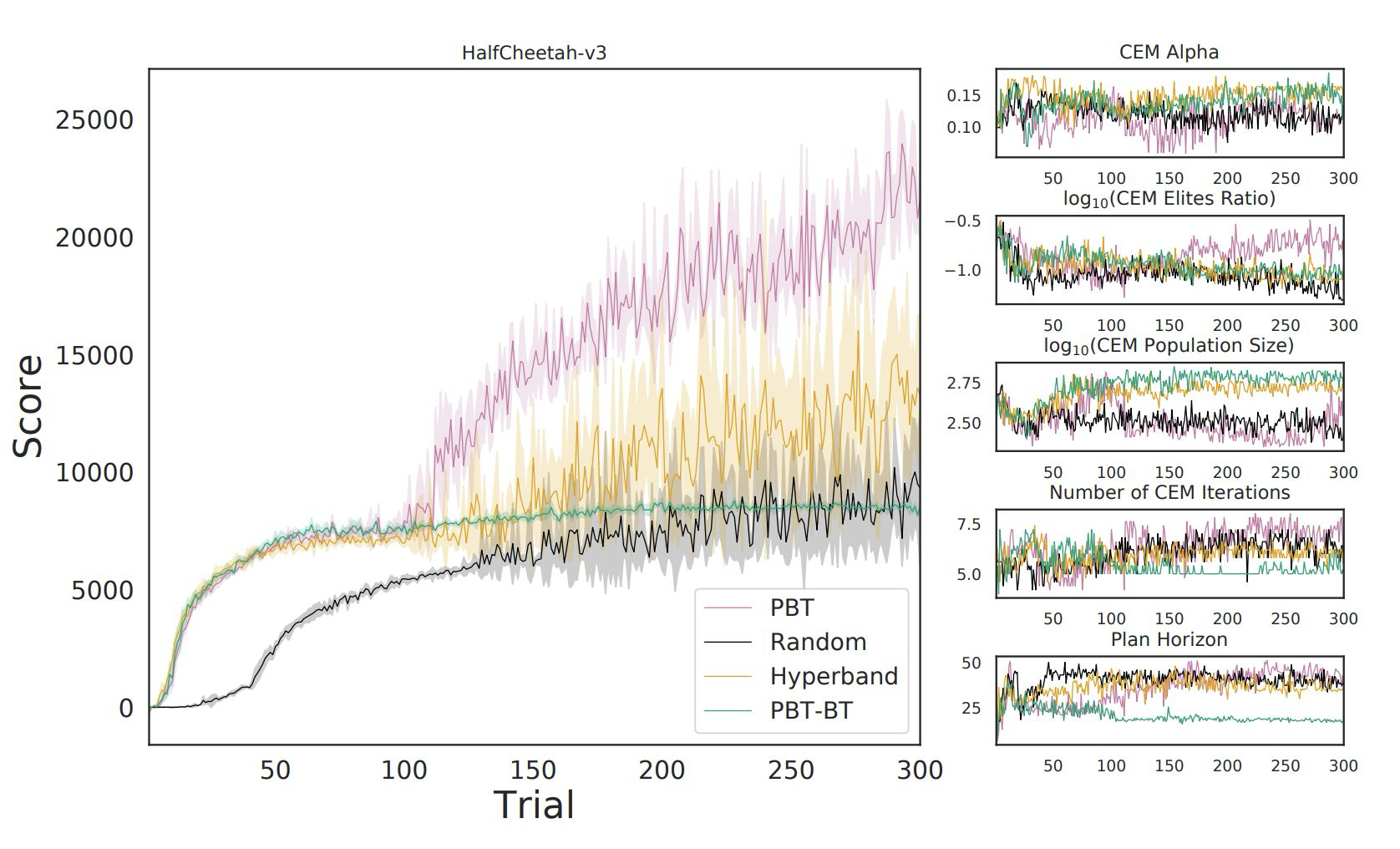
- Result. Automated HPO beats human-expert tuning across MuJoCo tasks (bottom-left), and dynamic tuning yields further gains over the best static configuration. Our results found a bug in mujoco that allows halfcheetah goes wildly like a helicopter.
- Takeaways. The paper also dissects which hyperparameters (plan horizon, learning rate, etc.) drive stability and final reward in MBRL.